Inference in machine learning is the stage where a pre-trained model is used to process new data and produce a result. Unlike training, where the model learns patterns from datasets, inference involves applying the model in real-world scenarios.
Simply put, learning generates the “knowledge” of the model, and inference uses it to make predictions, analyze, or generate a response.
Where AI and LLM inference is used
Inference underlies all working AI systems: chatbots and LLM, real-time data analytics, user query processing, forecasting, and working with data streams (for example, from IoT devices).
Why AI inference is important
The effectiveness of the inference depends on:
- system response rate
- cost of computing
- scalability of AI solutions
- quality of user experience
It is inference that determines how much AI can be used in production.
Key features of neural network inference
The inference of neural networks has a number of key features that affect its application in real systems:
- Static nature of the model
After completing the training, the architecture and weights of the model are fixed. At the stage of inference, the model is not re-trained, but uses already formed patterns without changing the parameters. - Working with real data
The inference occurs on “live” input data — user texts, video streams, sensor signals, or other sources. This data often differs from the training data in terms of quality, format, and distribution. - High speed requirements
In many scenarios, latency is critical: chatbots must respond instantly, security systems must analyze video in real time, and autonomous systems must make decisions in milliseconds. - Resource constraints
Unlike training, inference is often performed not on powerful GPU clusters, but on more limited devices such as smartphones, edge servers, and IoT devices.
Even a high-precision model loses its practical value if the inference is too slow or requires excessive computing resources.
LLM training vs inference: what is the difference
Learning and the inference of large language models (LLM) are two different stages of AI work, which differ in tasks, resources, and results.
LLM Training
LLM training is the process of forming a model based on large amounts of text data. The model learns to predict the next word by analyzing billions of examples and gradually adjusting the weights of the neural network.
This stage requires:
- huge amounts
- cluster data from thousands of GPUs
- long time (weeks or months)
Examples: training GPT-4 or DeepSeek-V3 level models.
LLM inference
LLM inference is the use of a pre-trained model to generate responses to user queries. The model receives the prompt, processes it, and generates a response based on fixed parameters.
At this stage, the model:
- is not re-trained;
- does not change the weights;
- only works with the current query.
Inference is what happens every time you use ChatGPT, Llama, and other LLM systems.
LLM training vs inference comparison table
This is how LLM training and inference differ:
| Criterion | LLM Training | LLM Inference |
| What happens | Adjustment of billions of parameters on large datasets | Generation of responses based on user requests (prompts) |
| Model changes | Weights are continuously updated during training | Model parameters are fixed and do not change |
| Duration | Long computations: weeks or months | Fast processing: seconds per request |
| Frequency | Performed once or periodically during fine-tuning | Performed on every user request |
| Hardware | Clusters of hundreds or thousands of GPUs | One or several GPUs, sometimes a CPU is sufficient |
| Data volume | Petabytes of data and trillions of tokens | A single user request (from short text to long prompt) |
| Cost type | Capital expenditure (one-time large investment) | Operational expenditure (cost per request) |
LLM inference from a business perspective
LLM inference is the stage at which the model begins to bring real value: it processes user requests and performs application tasks. This is where AI is used in products – chatbots respond to customers, AI assistants write code, and systems automatically translate documents and analyze data.
Unlike training, which is conducted once or periodically, inference is performed continuously – often millions of times a day in large-scale services.
Therefore, the effectiveness of inference becomes a key factor for business. Even a small reduction in the cost of a single request or faster processing at scale leads to significant savings and improved system performance.
Cloud infrastructure for AI inference
Where AI inference is used in real-world applications
Inference AI is the basic layer of modern digital infrastructure that works unnoticed by the user, but is used almost everywhere.
Text Processing (NLP)
chatbots respond to clients and process requests, and machine translation systems automatically translate texts, documents, and websites into different languages.
Computer vision
Surveillance cameras analyze events in real time, medical systems help identify pathologies in images, and drones assess the condition of fields and crops.
Recommendation systems
Streaming services select movies and music, and marketplaces make personalized product recommendations based on user behavior and history.
Finance
Anti-fraud systems detect suspicious transactions in real time, trading algorithms process market data, and scoring models assess credit risks.
Industry
AI predicts equipment breakdowns, detects manufacturing defects, and helps robots in warehouses work autonomously and in a coordinated manner.
Healthcare
The models help diagnose diseases, analyze medical data, and support real-time monitoring of patients’ condition.
Local inference
A separate area is the execution of models on the user’s device. Smartphones process photos and recognize faces locally, and industrial equipment makes decisions without connecting to the cloud, which increases speed and privacy.
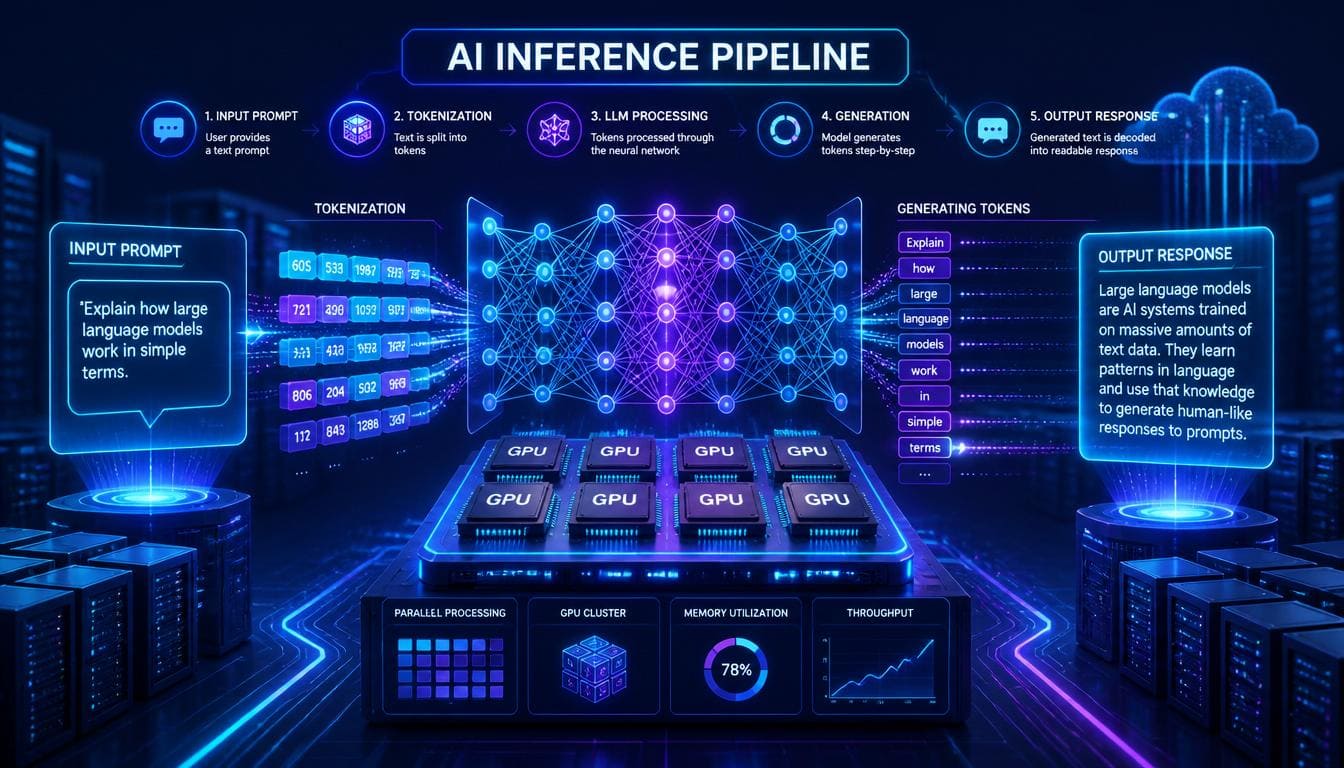
How AI inference works step by step
The inference of a language model is the process of converting an input prompt into a response. The generation takes place sequentially, token by token, using fixed weights of the model.
Step 1. Receiving the request
The user sends a text query (prompt), for example: “Which GPUs are suitable for LLM?”.
Stage 2. Tokenization
The text is divided into tokens, which are small semantic fragments (words or parts of words). Each token is then converted to a numeric format that is understandable to the model.
Stage 3. Context window
All tokens (request, system instructions, dialog history) are placed in the context window of the model. Its size is limited (for example, 8k–128k tokens). The larger the context, the higher the load and the slower the inference.
Stage 4. Autoregressive generation
The model generates a response based on one token:
- predicts the next token based on the current context
- adds it to the sequence
- repeats the process until the response is completed
The speed and behavior are affected by the parameters:
- temperature — controls the randomness of the response
- max tokens — limits the length of generation
Stage 5. Forming the response
The generated tokens are converted back to text and returned to the user, either immediately or streamed.
Due to the autoregressive nature, each new token requires repeated computation, so long context and complex queries increase the time and cost of inference.
Factors affecting AI inference speed and cost
Inference performance determines model response time and operational cost. It depends on a combination of hardware characteristics, model architecture, and request processing strategy.
Key factors table
| Factor | Impact | Optimization |
| Model size | Latency and memory usage | Quantization, distillation |
| Prompt length | Request processing time | Context compression and optimization |
| GPU type | Compute speed | Use of H100/A100 and similar GPUs |
| Batching | Throughput | Continuous batching |
| Number of GPUs | Scalability | Tensor / pipeline parallelism |
Hardware, model size and infrastructure impact on inference
Hardware part
The choice of hardware directly affects performance. The CPU is suitable for simple tasks, but inefficient for LLM due to limitations in parallel computing. The GPU provides high throughput due to thousands of cores, and the TPU and NPU are optimized specifically for neural network operations and work more energy-efficient.
Model size and memory
The larger the model, the higher the computational load. For example, the 70 billion parameter model requires significantly more resources than the 7 billion version. Large models (for example, 175B parameters) can take up hundreds of gigabytes of memory, and memory bandwidth is often the bottleneck.
Input and generation length
The attention mechanism in transformers has a quadratic complexity: each token interacts with the others. Therefore, doubling the context length can increase the calculation time by about 4 times. Long answers also increase the cost, as the generation goes on token by token.
Infrastructure and accommodation
The cloud allows you to flexibly scale calculations and use powerful GPUs on demand. Local inference reduces delays and increases privacy, as data does not leave the device. Hybrid architectures combine both approaches.
Concurrency and loading
The effectiveness of the inference depends on the number of simultaneous requests. Batching increases GPU utilization by combining multiple requests into a single processing. Continuous batching allows you to do this dynamically. For large models, computing is distributed between several GPUs (tensor and pipeline parallelism).
How to optimize AI inference performance
Optimizing the inference reduces the cost of calculations and reduces the delay in the model’s response. In practice, a combination of several approaches is used.
Step 1. Quantization of the model
Quantization reduces the accuracy of the weights (for example, from FP32 to INT8 or FP16), which reduces memory consumption and speeds up calculations.
As a result, the model becomes 2-4 times lighter, and the inference becomes faster, while the quality is usually maintained at 95-98%.
Step 2. Distillation and trimming of the model
Distillation transfers the knowledge of a large model into a compact one (“teacher → student”), and pruning removes insignificant parameters.
This allows you to significantly reduce the model (for example, from 175B to 13B parameters) with minimal loss of quality.
Step 3. Query Batching
Combining multiple requests into a single batch increases GPU load and increases throughput.
Continuous batching allows you to process requests dynamically, without waiting for a fixed set. This increases productivity several times.
Step 4. Caching calculations
Caching repetitive calculations reduces the load on the model.
KV-cache is especially effective for transformers — it speeds up generation for long or similar queries. Speculative decoding is also used, where the light model predicts tokens in advance, and the main model verifies them.
Step 5. Parallelism and load balancing
For large models, the distribution of calculations between GPUs is used.:
tensor parallelism — separation of model layers
pipeline parallelism — division by calculation stages
data parallelism — parallel query processing
High-speed connections (NVLink, InfiniBand) reduce delays between devices. This is critical for models with 100B parameters and higher that do not fit into the memory of a single GPU.
Where to run AI inference: deployment options
The choice of infrastructure for inference affects the cost, speed, and scalability of the solution. There are three main approaches.
Own infrastructure (on-premise)
It is suitable for large companies with constant high workload and strict data requirements.
High CAPEX: from hundreds of thousands of $ per GPU server
Deployment: 2-6 months
Scaling: slow, through purchase of equipment
Control: maximum, complete isolation
The disadvantage is the high cost of entry and difficult operation.
Dedicated server rental
A balance between control and flexibility.
No capital expenditure, just rent
Deployment: 1-3 days
Performance: stable and predictable
Scaling: adding servers in a few days
It is suitable for stable production loads without investing in hardware.
Cloud infrastructure
Maximum flexibility and quick start.
Launch: in minutes or hours
Zoom in: automatically
Payment: for use only
Suitable for: pilots, variable load, fast launches
The best option for starting and dynamic projects.
What to choose
Cloud – for flexibility and a quick start
Dedicated – for stable load
On-premise – for large long-term systems with a high level of control
Cloud infrastructure for AI inference (ITGLOBAL.COM)
ITGLOBAL.COM provides a cloud platform for LLM and AI inference in Tier III data centers in 10 countries.
Cloud infrastructure for AI inference
Key features of AI inference infrastructure
GPU infrastructure
Supports NVIDIA A100, H100, and L40S, fast Intel Xeon CPUs, and NVMe storage for minimal model loading delay.
Scaling
Automatic GPU addition when the load increases and shutdown when the load decreases. Payment is only for the actual use.
24/7 support
Infrastructure monitoring, incident response, and assistance in customizing specific models.
Quick start
Launch in minutes via a web interface with ready-made stacks: vLLM, TensorRT-LLM, Hugging Face TGI.
Conclusion: why AI inference matters for business
Inference is a key stage of LLM work, where the model brings value to the business. Optimization and the right choice of infrastructure can reduce the cost of requests and increase system speed, making AI projects scalable and cost-effective.








